March 19, 2021
Make your everyday decision data-driven with a home crafted ETL process
by Dane Marjanović, Junior Data Engineer
What to expect when you’re expecting?
Ever since she exclaimed “It’s a girl!”, your life has become a rollercoaster of joy, impatience but also some important decisions-to-be-made. One critical amongst them would probably be – how to name your firstborn? That’s the item a lot of spears are getting broken against – you feel the pressure from all around – almost everyone, her parents, your parents, grandmas, grandpas, known and unknown relatives feel entitled to an opinion. “It should be named after your gran-grandma, a partisan hero…her aunt, librarian and Olympian sharpshooter…you ought to shoot for a traditional/international/{placeholder} name…”, all these advices resonate in your head and at one point you realize you need help – and it comes in form of data, to drive your decision towards quieter waters.
There is this other thing as well – you, as a serial binger are aware that the future may not be so bright for your hobby, so you want to use the remaining time to watch all the stuff you might’ve missed – but you need to choose wisely as you can’t have it all – you’ve guessed it, data will help here too.
ETL – historically and currently
ETL stands for extract, transform and load, a process in which data is taken from various sources, transformed to a common format/aggregated, and then imported into a source database, in most cases a data warehouse (DWH). From there, data is used for various kinds of reporting to satisfy business needs.
Data sources could be various – a relational database, flat files, textual files, CSV/XML/JSON, etc., and the Extract part needs to validate the input data and make sure it’s properly formatted. The goal of Transform is to have data cleansed, as well as perform other operations where needed – to omit unneeded data, aggregate, derive new values by combining existing, normalize it by splitting into more atomic values etc. This step can be done by using a temporary database as an intermediate repository. From there, data is loaded either to the staging database where some testing reporting is done or directly into the data warehouse (which is usually a relational database). However, we can see that steps in ETL process can vary in number, complexity, and methodology.
A modern variant/alternative to ETL is ELT (extract, load, transform), an approach where data, upon extraction, is directly loaded into data lake. In this case, the transform part is performed on-demand. This allows getting the data more quickly and is more suitable for businesses that require a lot of real-time analytics and reporting.
Data pipeline – is it something you smoke?
Another commonly used term related to data processing is data pipeline. In general, a data pipeline is a sequence of steps/actions that take data from one source and migrate it to a certain destination. In this sense, ETL can be viewed as just one form of data pipeline. On the other hand, this term can be used in a more specific way, where a pipeline would be a series of steps within a single ETL architecture performing a specific task against the data – and ETL would consist of multiple pipelines.
The tools of the trade
Nowadays, there are a lot of readily available ETL tools that make data engineers’ lives easier, so in most cases, there is rarely a need to develop your own solution from the scratch. In our case, since our business requirements bar is not set too high, we can devise our own solution.
Since we’re working on a rather small scale, we’ll be using Python and PostgreSQL for our ETL. Python will handle ETL part and PostgreSQL will be our source database. The plan is to clean, format, and normalize data with Python, load it into PostgreSQL, and then do some merging thereby creating views that will join multiple sources together.
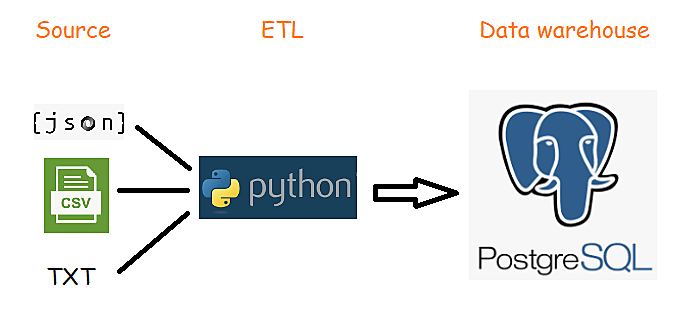
But where to get my data?!
For TV shows data we can find some readily available, free to download datasets – i.e. on kaggle.com. Most of them are in CSV format so we’ll just have to do some cleansing and transformation to get them prepared for the loading.
In case of our names data, we’ll pretty much need a list of common female names of Bosnia and Herzegovina. To create that list, we’ll apply some web scraping*. Going into the details of scraping is out of the scope of this post, but in short, we’ll get the raw text data from a website.1 Scraped data will be formatted and stored into a plain text file.
Preparing the ingredients
Once we obtained our source files, we can start planning how to compose the transform part. We’ll decide which data can be thrown as unneeded and which can be normalized to better suit the source. Here is how it might look like on one of our source files:
We can omit the ‘Poster_link’ and ‘Certificate’ columns as we won’t really need them. Then, it would be useful to split ‘Runtime_of_series’ column into two columns, ‘release_year’ and ‘end_year’ as numeric values which would make data more granular and enable filtering it better. The same goes with ‘Genre’ column – in its current form it does not satisfy even the 1st normal form and makes filtering by genre rather difficult, so we’ll split it into single values. Column ‘Runtime’ consists of show runtime in minutes represented as a string, which is not suitable for querying, so we’ll remove the ‘min’ portion and convert values to a numeric format. Columns ‘Star1’ – ‘Star4’ on the other hand basically represent the same attribute hence should be merged into a single column.

Shapeshifting the data
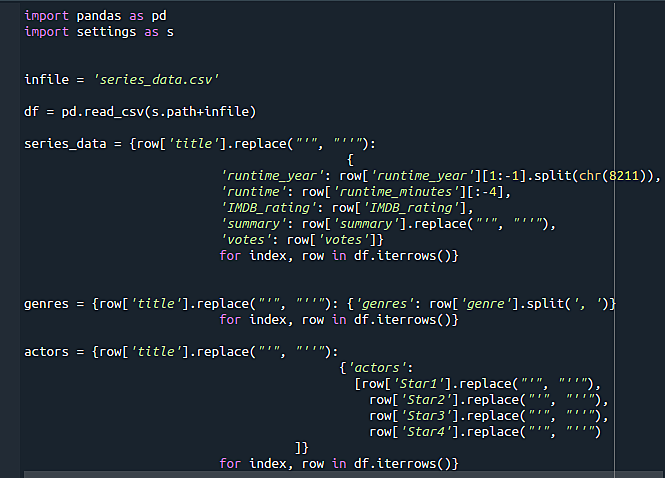
We can now start building the transform pipelines. There are various Python libraries that can be used, and for our purposes of loading and formatting input data we’ll mainly use pandas, csv and json and pycopg2 for connecting Python and Postgres.
As we can see in the following screenshot, the pipeline (actually a ~10 LOC script but pipeline sounds more serious and gives an impression we know what we’re doing) will be handling a couple of tasks:
- loading dataset
- transforming it to a pandas dataframe which is great for tabular data
- exporting to set of dictionaries (which can be dumped into a JSON easily)
- during the previous step, necessary modifications on the data will be performed – removing characters that could be causing - troubles upon import to Postgres (single quotes as part of strings in particular), splitting and merging data, as described earlier.
Final destination
After we finished building scrip…pipelines to transform all datasets we want and tested them to make sure the return data is valid and well-formatted, we are ready to create pipelines that will load the data to our database. I won’t go into much detail here because this part is done pretty much routinely if previous steps were thorough enough and data was prepared well – basically this would consist of:
- connecting Python with Postgres
- send DDL statements (create destination tables)
- inserting the data into database
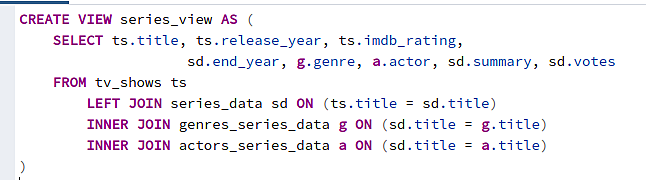
Once we’re done with these steps, got them tested, and made sure data is in the database and looks good, we will do some massaging in SQL to make data more user-friendly by creating views (in a more real-life scenario, we’d probably denormalize data by merging into bigger tables, but for our tiny dataset views would do just fine).
The fun part
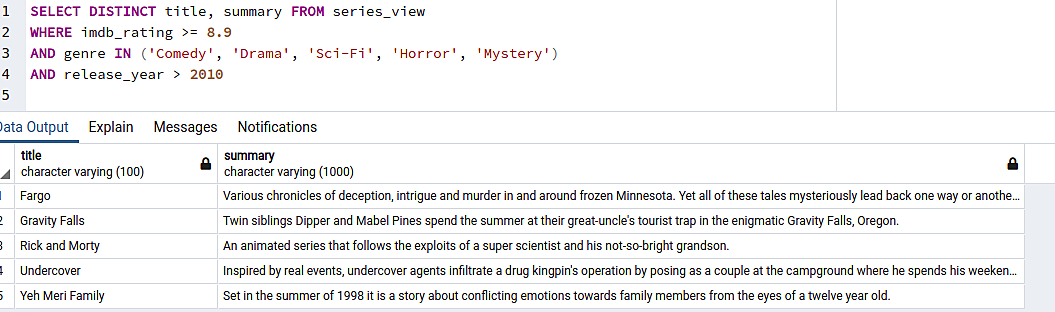
So, the heavy lifting is done, and we can finally get to consume your data. We assemble a query filtering the data so we get only the best-rated, recent content within the genres we prefer…only to realize we’ve already seen all of them.
As for the choosing-the-name part, after a second thought we realized we might not need the complicated and buggy DIY process as described previously – only a list containing enough names, few good conditions, and a bit of luck:
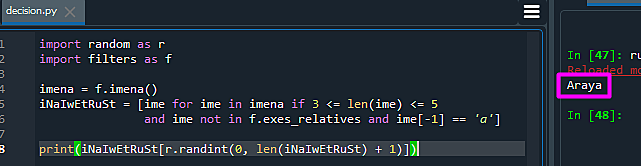
Well, what else could you expect from a sloppy algorithm, but a most computer-sciency name in your names array (pun intended) it could find.2
(Note: The actual ETL process is, of course, a lot more complex than the one described in this post. This is more a DIY mockup that tries to bring the topic closer to a reader not so familiar with data processes. After all, data engineers are them serious folks, ain't they?)
1. Disclaimer - data was scraped in a non-abusive manner, mostly as a one-time process that did not affect the site traffic significantly. Also, scraped data (female names and their meanings) belongs to the public domain. Lastly, data was not used for any commercial purposes but solely for the needs of writing this blog post.
2. Rumor has it that this might actually be based on a true story - the author of this post might have had used a similar process to name his first child, but we've been unable to confirm this...
Industries
Expertise
Android
iOS
Java
Javascript
.Net
Ruby
Python
C/C++
Flutter
Angular
Blockchain
© 2025 Klika d.o.o.